Fotomontaje con el esquema principal del modelo. Omicrono
Meta acelera para luchar contra ChatGPT: su IA podrá combinar 6 tipos de datos distintos
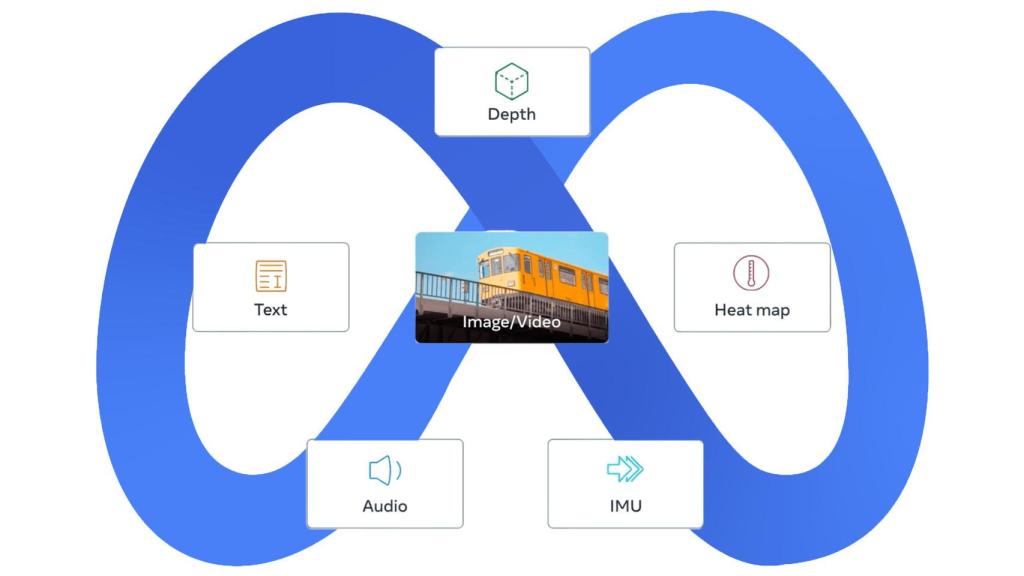
Es el primer modelo capaz de vincular información en un solo espacio de incrustación de hasta 6 modalidades, que incluyen datos visuales o térmicos.

En la fiebre de la inteligencia artificial, nos hemos encontrado con todo tipo de amantes y detractores. Tanto en España como en el resto del mundo la IA está siendo el objetivo de todas las empresas, llevando a una cruenta batalla por su liderazgo entre Microsoft y Google. Ahora, la última en sumarse es Meta, que ha anunciado un nuevo modelo de IA de código abierto.
Tal y como ha explicado la propia Meta en un comunicado, han conseguido desarrollar un modelo de inteligencia artificial de código abierto que es capaz de vincular distintos tipos de flujos de datos, incluyendo texto, datos visuales, temperatura o audio. Por el momento, este modelo no está en etapa comercial, es decir, que es más un proyecto de investigación que por el momento no tiene aplicaciones prácticas.
El modelo, apodado ImageBind, es capaz de datos tales como datos visuales (imagen o vídeo), datos de movimiento generadas por unidades de medición inercial o texto y audio. Así, este modelo que por el momento no está pensado para consumo pueda crear sistemas multisensoriales y experiencias inmersivas, que podrían llegar a aplicarse en herramientas de IA en el futuro.
Una IA multisensorial
Para que entendamos la idea en la que se basa este modelo, debemos entender cómo funcionan los modelos de IAs generativas de imágenes. Los ejemplos más claros son Stable Diffusion, Midjourney o DALL-E, capaces de convertir texto a imágenes. Estos generadores dependen de sistemas que vinculan tanto texto como imágenes en sus fases de entrenamiento, cuando se están desarrollando sus bases de datos.
De esta forma, los sistemas buscan patrones en los datos visuales mientras conectan esa información con las descripciones de esas mismas imágenes. Así, se generan imágenes que siguen las pautas de las entradas de texto de los usuarios. Básicamente buscan patrones en los datos visuales que concuerden con las descripciones de estas mismas imágenes para generar la imagen.

Modalidades del modelo. Meta
Pues en este sentido, Meta amplía ese concepto. Este es el primer modelo capaz de vincular información de seis modalidades en un solo espacio de incrustación o índice multidimensional; datos visuales (vídeo o imagen), térmicos (imágenes infrarrojas), texto, audio, información de profundidad e incluso lecturas de movimiento generadas por unidades de medición inercial.
En palabras de la compañía, este modelo podría permitir que las máquinas consiguieran una especie de comprensión holística, que pudiera conectar los objetos en una foto con sus sonidos, su forma 3D o incluso su temperatura. Por ejemplo, usando ImageBind sobre la herramienta de investigación de Meta, Make-A-Scene, esta podría crear imágenes a partir de audio, como por ejemplo imágenes de selvas tropicales a partir de sus sonidos.
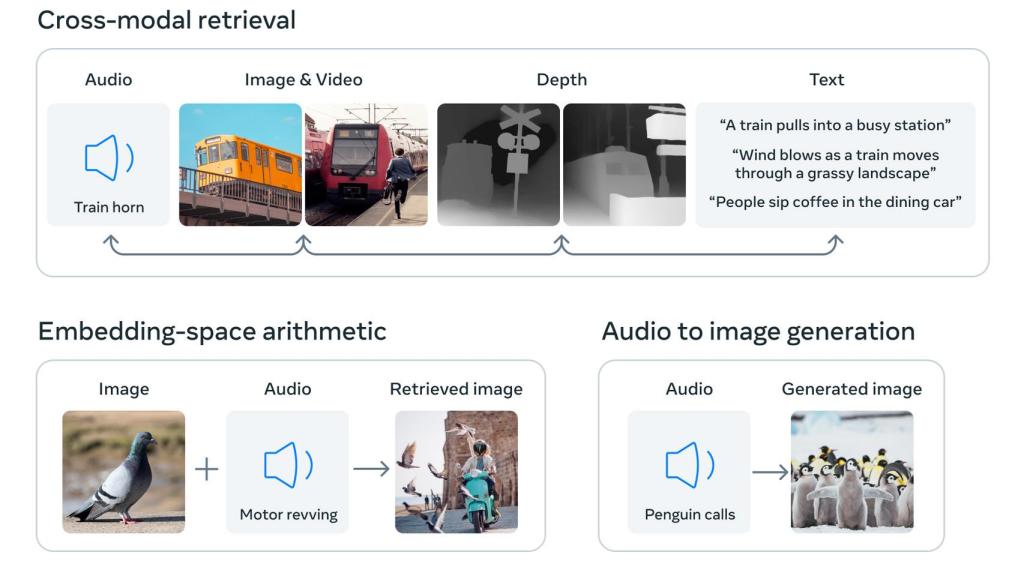
Ilustración del modelo. Meta
Lo que busca Meta con este sistema es que los modelos equipados con ImageBind puedan hacer referencias cruzadas de estos datos de la misma forma en la que lo hacen los sistemas actuales para las entradas de texto. Es decir, un hipotético dispositivo de realidad virtual que tuviera este sistema sería capaz, al menos sobre el papel, de generar entradas visuales y auditivas, además de entradas de movimiento. En un caso ideal, podría pedirle que emulara una caminata por la selva, que ubicaría al usuario en la selva e imitaría los sonidos característicos de la selva y los movimientos de las plantas.
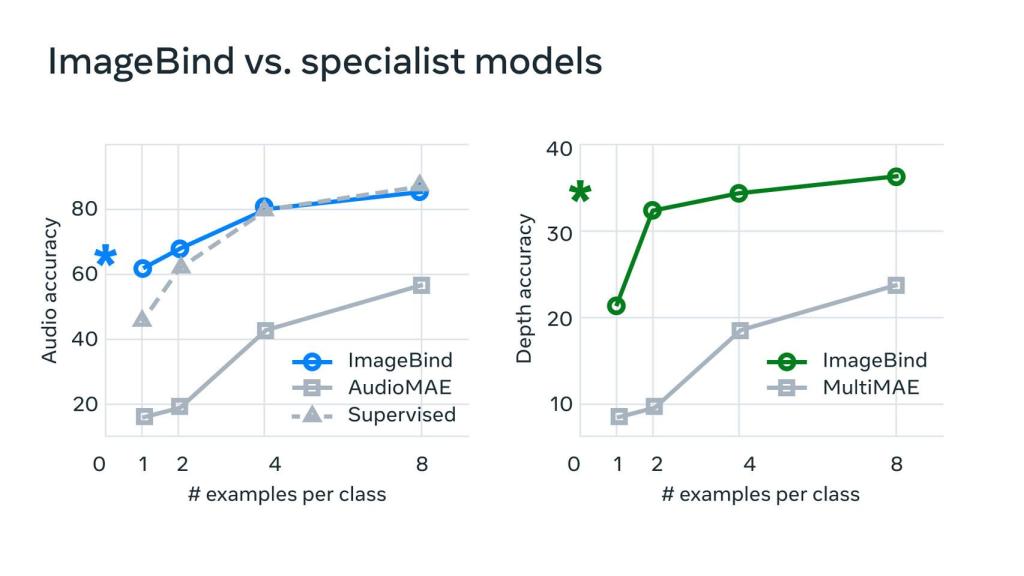
ImageBind contra otros modelos especialistas. Meta
De nuevo, esta investigación podría implicar que modelos futuros puedan recibir nuevos flujos de información sensorial, incluyendo "señales de resonancia magnética funcional del tacto, el habla, el olfato o el cerebro". Esta investigación, en palabras de la firma, "acerca un paso más a las máquinas a la capacidad de los humanos para aprender de forma simultánea, holística y directa a partir de muchas formas diferentes de información".
Por si fuera poco, ImageBind asegura que los datos emparejados con imágenes son suficientes para unir estas seis modalidades. De esta forma, el modelo puede interpretar el contenido "de manera más holística", permitiendo que estas distintas modalidades puedan hablar entre sí y puedan encontrar vínculos entre sí sin observarlas juntas. ImageBind, en definitiva, puede asociar audio y texto sin verlos juntos, por ejemplo.
[La hipocresía de Musk: pide parar la inteligencia artificial, pero trabaja en su propio ChatGPT]
Como en el caso del metaverso, este modelo puede presentar ideas muy especulativas y abstractas por el momento. Es más que probable que, por el momento, las aplicaciones más inmediatas de estas investigaciones sean más limitadas de lo prometido. ImageBind abre la puerta a cómo futuras versiones del modelo podrían incorporar otros flujos de datos, para permitir entre otras cosas generar audio para que coincida con la salida de vídeo.
Una idea especulativa, sin duda, pero que es llamativa debido a su carácter de código abierto, que permite a terceros examinar estos sistemas y mejorarlos, además de permitir otras herramientas e investigaciones usando estos datos. Una práctica a la que se han opuesto firmas como OpenAI, debido a que creen que actores con malas intenciones podrían usar estos modelos de IA.



