IU sube 3,6 puntos y Ciudadanos 3 a costa de Podemos, PSOE y PP
Los populares volverían a ganar con un 27,5% de los votos aumentando su ventaja sobre el PSOE, que obtendría un 19,3%.
Noticias relacionadas
La segunda parte de nuestra encuesta la hemos dedicado a la intención de voto. Hemos pedido a los entrevistados que nos dijesen por qué partido votarían si hubiese elecciones mañana. Es una información clave por dos razones: porque es posible que volvamos a las urnas y porque los partidos, estos días, negocian con un ojo puesto en las encuestas. El gráfico siguiente ofrece nuestra estimación de voto.
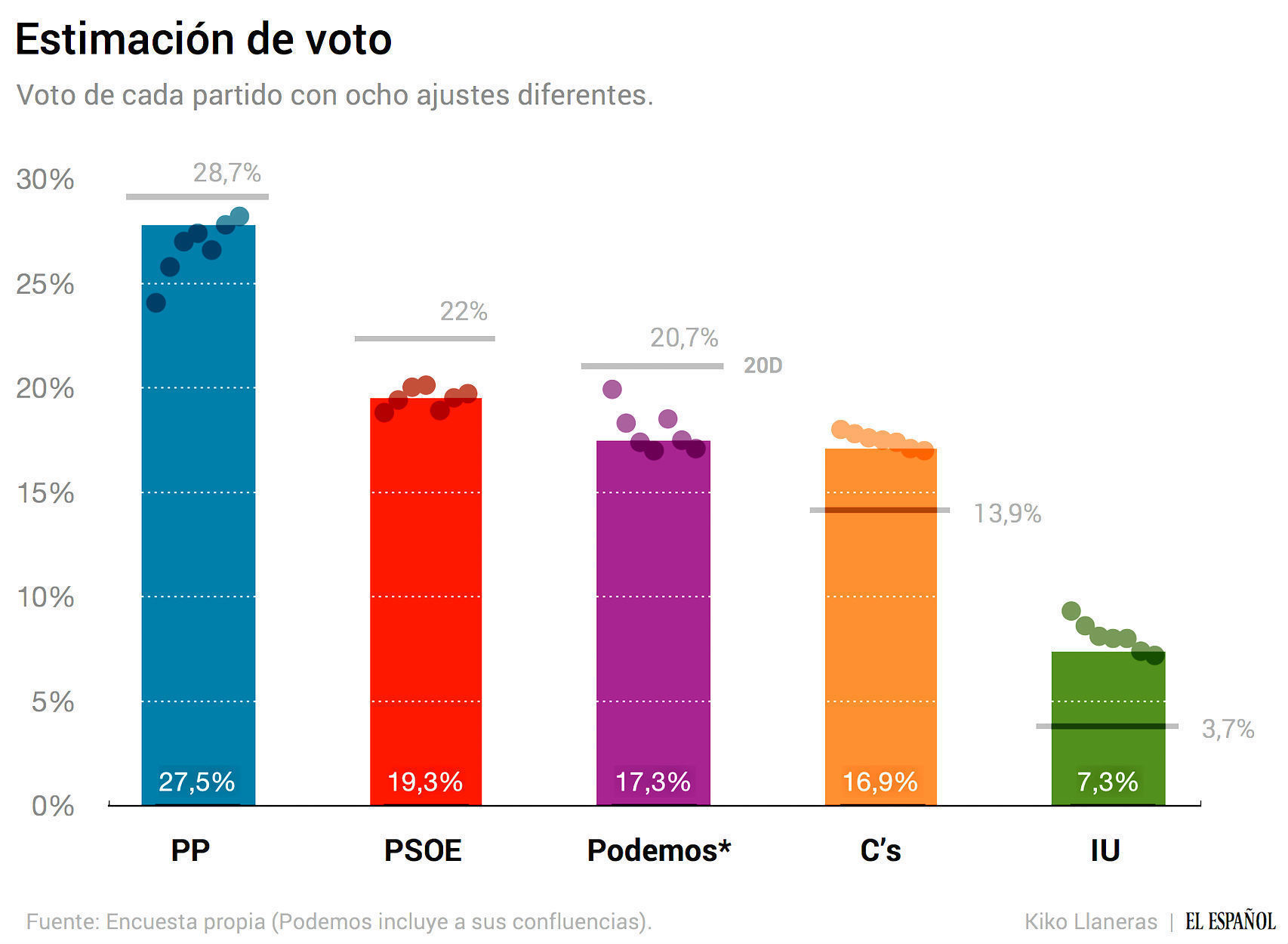
De acuerdo con nuestros datos, el PP lograría alrededor del 27% de los votos, el PSOE el 19,3%, Podemos el 17,3%, Ciudadanos el 16,9%, e Izquierda Unida, el 7,3%. Los grandes beneficiados desde diciembre serían Ciudadanos e Izquierda Unida. Caerían sobre todo el PSOE y Podemos.
Estos movimientos pueden explicarse de diferentes maneras. Cada uno puede tener sus hipótesis. Pero es pertinente cierta precaución con las subidas de Ciudadanos e Izquierda Unida. Las elecciones no están cerca, ni siquiera están confirmadas, y es posible que algunos encuestados estén siendo 'expresivos'. No ha habido campañas ni están pensando en cosas como votos útiles. Una parte de quienes dicen que votarán por Ciudadanos o Izquierda Unida quizás acabarán regresando al PP o Podemos. Este tipo de sesgos pueden darse y juzgarlos depende del lector.
Otro dato de la encuesta ayuda a explicar los cambios en la intención de voto: la cantidad de personas que no repetirán su voto. El gráfico siguiente muestra a quién votarían hoy quienes en diciembre votaron por PP, PSOE, Podemos, Ciudadanos e Izquierda Unida.

El Partido Popular e Izquierda Unida son los partidos con más fidelidad: un 82% de quienes les votaron en diciembre repiten su voto. Ciudadanos mantiene al 70% de sus votantes, el PSOE al 66% y Podemos al 60%.
Esa baja fidelidad explica la caída de Podemos: cuatro de cada diez personas en nuestra encuesta que afirman haber votado a Podemos en diciembre declaran ahora una intención de voto distinta. Un 11% votará a Izquierda Unida —lo que contribuye a explicar su subida—, un 9% al PSOE y un 4% a Ciudadanos. Otro 5% afirma que no votará y un 4% que no lo sabe.
Haciendo distintas cocinas
En el primer gráfico he incluido siete estimaciones diferentes. Las barras representan mi estimación central y cada punto un método ligeramente distintos. La tabla siguiente muestra cada estimación y después las describo brevemente.

Hay algunos ajustes comunes a todos los métodos. La muestra está calibrada para que sea representativa por edad, sexo, nivel de estudios, situación laboral y provincia. He atribuido los "no sabe/no responde" de esta forma: un 75% asumo que no votarán y el 25% restante asumo que son votantes homogeneos. Por último, he ignorado nuestros datos para los partidos con menos del 3% de votos (ERC, DL, etc.) porque nuestra muestra no es suficiente para estimarlos. Asumo que esos partidos obtendrían unos resultados similares a los del 20 de diciembre.
Las diferencias entre estimaciones aparecen en otro factor clave: el recuerdo de voto. En la encuesta hemos preguntado por el voto del 20D y gracias a esa pregunta sé que en nuestra muestra original estaban sobrerrepresentados Podemos y Ciudadanos. Teniendo eso en cuenta podemos reponderar la muestra. La otra variable que he usado en los modelos de estimación es la probabilidad de votar que declara cada encuestado.
Así resultan nuestros siete modelos.
Modelo en bruto. Estimación de voto sin calibrar por recuerdo de voto ni por la probabilidad de votar.
Modelo M5, M8, M9. Estimaciones de voto ponderando las 1.000 observaciones para ajustar el recuerdo de voto de la muestra a los resultados de las elecciones del 20 de diciembre de 2015. Hacemos el ajuste al 50%, al 80% y al 90%.
Modelo M5b, M8b, M9b. Estimaciones de voto como las anteriores, pero considerando que sólo son votantes quienes declaran que votarán con una probabilidad superior a cinco sobre diez. El modelo M8b es el que he elegido como mi escenario central.
Estos modelos son, de momento, provisionales. Mi propósito es ir sofisticándolos en el futuro e incorporar otros. También serán más fáciles de calibrar conforme tengamos una serie de datos. Pero mi propósito es mantener siempre diferentes modelos de estimación porque eso nos ofrece una medida de incertidumbre. Si los diferentes métodos dan estimaciones similiares, podemos considerarlas más fiables. Si difieren, deberíamos ser más cautos.
Mañana podréis leer la tercera y última entrega del sondeo electoral de EL ESPAÑOL.
Kiko Llaneras analiza la estimación de voto
Metodología
Se han realizado 1.000 entrevistas a partir de un panel online y aplicando cuotas por sexo, edad, provincia, tamaño de hábitat, nivel de estudios y situación laboral. Netquest ha proporcionado los datos en bruto a EL ESPAÑOL. He sido yo —Kiko Llaneras— quién ha calibrado la muestra y producido las estimaciones.
Queremos que el sondeo sea transparente. Trataremos de explicar a los lectores el proceso de estimación y se publicarán todos los datos. En breve compartiremos los 'microdatos' con las 1.000 entrevistas, que incluirán tanto los datos ajustados según nuestras calibraciones como los datos brutos facilitados por Netquest. ¿El objetivo? Que cualquier persona interesada —académicos, otros medios o los propios lectores— pueda usar las cifras para hacer sus propios cálculos o responder otras preguntas.
Ficha técnica
Ámbito: nacional.
Universo: población española de 18 años y más.
Trabajo de campo: entrevistas online a partir de un panel de captación activa (sólo por invitación) certificado con la norma ISO026362. Realizado por la empresa Netquest.
Tamaño de la muestra: 1.002 entrevistas obtenidas con cuotas por sexo, edad, provincia, tamaño de hábitat, nivel de estudios y situación laboral.
Ponderación: una vez obtenidos, los datos han sido ponderados para calibrar por sexo, edad, hábitat, estudios, situación laboral, el cruce de sexo y edad, y el cruce de estudios y edad. También hemos ponderado las estimaciones de voto para ajustar parcialmente el recuerdo de voto de la muestra a los resultados de las elecciones del 20 de diciembre de 2015. Algunos modelos de estimación consideran también la probabilidad de votar de cada entrevistado.
Error muestral: para un nivel de confianza del 95,5%, el margen de error de la muestra es del ±3,1%.
Realización del trabajo de campo: del 23 al 30 de marzo de 2016.



