
La nueva tecnología presentada por Meta permite traducir más de 200 lenguas distintas con resultados precisos.
La 'Torre de Babel' de Facebook: la inteligencia artificial que desafía a Dios y a las barreras lingüísticas
La actual Meta desarrolló en 2018 un motor de traducción capaz de trabajar con 50 idiomas; ahora supera las 200 lenguas de lo más dispares.

Según cuenta la Biblia, los descendientes de Noé se instalaron en Babilonia tras el diluvio universal. Allí, y todavía consumidos por el rencor hacia el Dios que dejó morir a cientos de miles de personas, decidieron construir una torre que llegara hasta los mismísimos cielos y vengarse, así, de la gran némesis de la Humanidad. Pero las prisas les pudieron a estos bienaventurados vengadores, hasta el punto de que comenzaron un ataque con flechas antes de haber culminado la ambiciosa estructura.
El resto, como suele decirse, es historia (o leyenda): Dios no dejó sin respuesta esta ofensa y decidió enfrentar a los babilonios entre sí, confundiendo sus lenguas y haciendo imposible que se comunicaran entre ellos. De ese desafortunado desencuentro entre los descendientes de Noé y nada menos que Dios vendría la actual heterogeneidad de idiomas que encontramos en la Tierra y, también, las dificultades para conversar, hacer negocios o simplemente mantener relaciones entre humanos que simplemente han tenido la fortuna de nacer en un lugar u otro del globo.
Esta situación no nos ha sido ajena como especie y ha marcado notablemente la configuración social y geopolítica a lo largo de los siglos. Las similitudes entre idiomas han favorecido el comercio, la adopción de lenguas comunes han permitido sentar lazos de amistad entre naciones enemigas y la capacidad de traducir e interpretar varias de ellas han facilitado desde la expansión de las democracias hasta la libertad de expresión en muchos polos del planeta.
Para burlar este castigo divino, la Humanidad ha ido desarrollando diferentes tretas y habilidades. Eso sí, hasta ahora todas ellas tuvieron su sustento en la capacidad de mortales en canalizar el conocimiento de varios idiomas y en la producción de manuales, guías y diccionarios con los que poder transmitir dicha sabiduría a nuevas generaciones de traductores e intérpretes. Un proceso claramente limitado y cuya escalabilidad a un terreno casi infinito como internet se antojaba claramente difícil.
No es de extrañar que herramientas como traductores online hayan sido de lo más anhelado en los orígenes de la red de redes y que, a fecha de hoy, sean una funcionalidad básica en el día a día de muchos de nosotros. Pero dichas tecnologías distan mucho de la omnipotencia necesaria para vencer en la contienda contra una deidad, tanto en calidad y precisión de los resultados que ofrecen como en la cantidad de lenguas que son realmente capaces de procesar.
En la actualidad, unos pocos idiomas (como el inglés, el mandarín, el español o el árabe) dominan la conversación en internet. Puede que para nosotros no resulten evidentes las dificultades que supone esa hegemonía lingüística para los habitantes de países con idiomas minoritarios, en sociedades con acceso limitado a recursos educativos en África o Asia. Sin duda, se antoja como una de las mayores brechas en el acceso digital y, también, en un freno directo a su desarrollo económico y social.
La osadía de Facebook
En estas, Meta -propietaria de Facebook, Instagram o WhatsApp- acaba de anunciar un salto adelante en este campo. Desde hace tiempo se vienen desarrollando esos modelos de traducción automática que mencionábamos anteriormente, pero apenas estamos rozando la superficie de su potencialidad. Por ejemplo, el primer motor de procesamiento de lenguaje natural de esta compañía (llamado LASER, en 2018) apenas procesaba cincuenta lenguas diferentes. La tecnología presentada ahora -NLLB-200, “No Language Left Behind”,- eleva este número a 200, con un nivel de calidad sin precedentes.
Entre esos idiomas encontramos el kamba o el lao, olvidados por la mayoría de los motores de lenguaje natural del mundo. Frente a las 25 lenguas africanas que suelen incluirse en las herramientas de traducción más usadas, el nuevo NLLB-200 trabaja con 50 de ellas.
Además, asegura la multinacional, este motor de traducción ha sido probado para medir la calidad de los resultados que ofrecen, no vaya a ser que los textos resultantes sólo sean comprendidos por algún pobre diablo. Para ello, la enseña ha creado un nuevo conjunto de datos de evaluación, FLORES-200, con el que ha medido el rendimiento de NLLB-200 en cada idioma para confirmar que las traducciones eran de buena calidad. ¿La conclusión? Mejora los actuales sistemas en un 44 % de media.
"La comunicación entre idiomas es uno de los superpoderes que brinda la inteligencia artificial, pero a medida que avanzamos en nuestro trabajo de IA, mejoramos todo lo que hacemos, desde mostrar el contenido más interesante en Facebook e Instagram hasta recomendar anuncios más relevantes y mantener nuestros servicios seguros para todos", añadía el propio Zuckerberg tras hacer público este avance de la técnica.
Ya usada en Facebook y Wikipedia
La tecnología NLLB-200 será publicada en forma de código abierto para que toda la comunidad pueda participar en su desarrollo, contribuir a esta particular 'torre de Babel' y beneficiarse de esta ruptura con los designios marcados por la diversidad lingüística.
Por lo pronto, la propia Meta ya va a utilizar -como es menester- esta tecnología en sus diferentes productos. Así pues, más de 25.000 millones de traducciones al día en la sección de noticias de Facebook, Instagram y otras plataformas podrán ser ejecutadas sobre la base de NLLB-200 y sus futuras evoluciones.
"Imagina poder visitar un grupo de Facebook que te encante, encontrarte con una publicación en idioma igbo o luganda, y ser capaz convertir esa información a tu propio idioma con solo pulsar un botón. Además, las traducciones precisas en varios idiomas también pueden ayudar a detectar contenido dañino e información errónea, proteger la integridad electorales y frenar los casos de explotación sexual y tráfico de personas en internet", explican desde la multinacional.
No sólo eso: esta clase de sistemas también pueden ayudar a avanzar en otros ámbitos del procesamiento de lenguaje natural, no solo de la traducción. Por ejemplo, en diseñar asistentes que funcionen correctamente en idiomas como el javanés o el uzbeko, o en crear sistemas que permitan introducir subtítulos precisos en oromo o suajili en películas de Bollywood.
Además, la compañía de Mark Zuckerberg colabora con la Fundación Wikimedia, la organización sin ánimo de lucro detrás de la Wikipedia, para mejorar sus sistemas de traducción. Recordemos que hay versiones de Wikipedia en más de 300 idiomas, pero la mayoría tienen muchos menos artículos que la versión en inglés, que ya cuenta con más de seis millones.
"Esta disparidad es especialmente notable para los idiomas que se suelen hablar fuera de Europa y Norteamérica. Por ejemplo, hay disponibles alrededor de 3.260 artículos de Wikipedia en lingala, un idioma hablado por 45 millones de personas en la República Democrática del Congo, la República del Congo, la República Centroafricana y la República de Sudán del Sur. Pero, por el contrario, el sueco dispone de más de 2,5 millones de artículos para 10 millones de hablantes en Suecia y Finlandia", detalla un comunicado oficial.
Por ello, el motor de traducción de Meta será usado para hacer accesibles artículos a más de 20 idiomas con pocos recursos (es decir, aquellos que no disponen de conjuntos de datos lo suficientemente grandes para entrenar los sistemas de IA). Entre ellos, se incluyen 10 idiomas que no estaban anteriormente disponibles en ninguna herramienta de traducción de la plataforma.
Cómo funciona NLLB-200
Los sistemas de traducción automática, basados en inteligencia artificial, se entrenan con datos. Para los sistemas de traducción de texto, este entrenamiento consiste en millones de oraciones emparejadas cuidadosamente entre combinaciones de lenguas.
Sin embargo, hay muchas otras combinaciones para las que no existe un gran volumen de oraciones paralelas, como, por ejemplo, entre el inglés y el fula. Los modelos de traducción actuales intentan suplir estas carencias extrayendo datos de la web. Aun así, los resultados a veces presentan una calidad bastante mejorable, ya que el texto origen es diferente para cada lengua. Y, a veces está lleno de errores gramaticales o incoherencias, le faltan tildes y otras marcas diacríticas.
Otra gran dificultad es optimizar un modelo único para que funcione con cientos de lenguajes sin que esto comprometa la calidad de la traducción, ya que, tradicionalmente, los mejores resultados se habían conseguido con modelos independientes para cada dirección lingüística. Pero este método no es fácil de aplicar en una herramienta con muchos idiomas, ya que el rendimiento y la calidad de la traducción empeoran cuantos más idiomas se añadan.
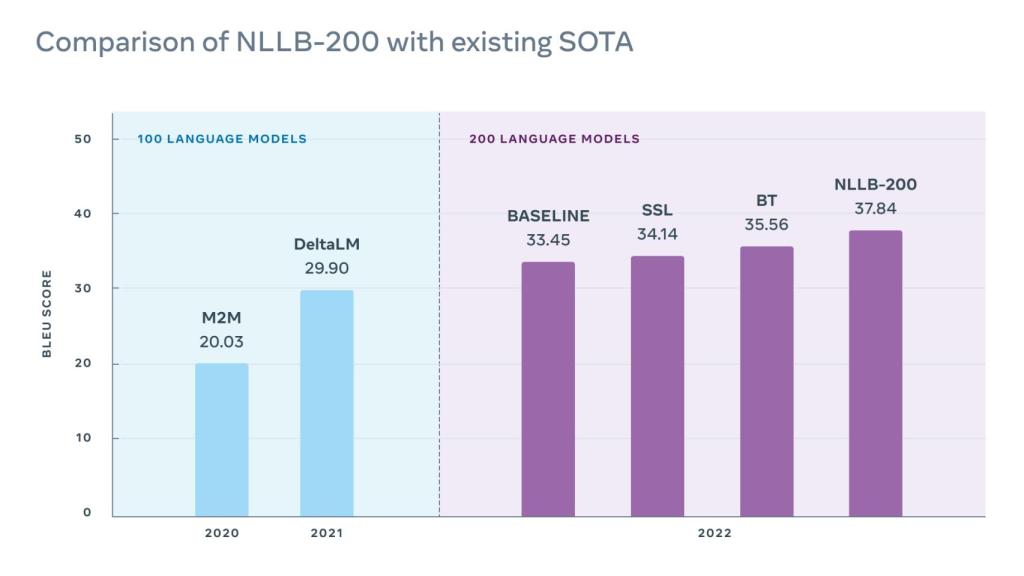
Comparativa de distintos modelos de procesamiento de lenguaje natural y traducción automática.
Los modelos de traducción también producen errores que no son fáciles de identificar. Estos sistemas están diseñados simulando redes neuronales que se utilizan en la generación de textos, por lo que a veces pueden producir errores como alucinaciones (afirmar algo como cierto aunque no sea así), declaraciones erróneas y contenido no seguro. En general, hay menos puntos de referencia y conjuntos de datos para lenguas con menos recursos, y, en consecuencia, es mucho más complejo probar y mejorar los modelos.
Por ello, aseguran desde Meta, sus ingenieros han trabajado para poner remedio a algunas de estas circunstancias. En concreto, la compañía ha mejorado su herramienta de representaciones de oraciones agnósticas del lenguaje, con supervisión automática y un nuevo modelo de aprendizaje profesor-alumno. También ha renovado completamente su canal de limpieza de datos para poder ajustarlo a 200 idiomas, incluyendo además listas de palabras tóxicas para evitar problemas en ese sentido.
Además, Facebook ha seguido un enfoque de aprendizaje curricular en dos pasos: "primero, entrenamos a los idiomas con muchos recursos durante ciertas épocas, lo que también contribuye a reducir el sobreajuste. Luego, debido a la escasez de datos en el corpus paralelo de los idiomas con pocos recursos, aprovechamos el aprendizaje de supervisión automática de los datos monolingües tanto de los idiomas con pocos recursos como de idiomas similares con muchos recursos, de forma que mejoramos el rendimiento general del modelo".
Además, Meta se dio cuenta de que, si mezclaba datos de retrotraducciones generadas para modelos bilingües de traducción automática estadística y traducción automática neuronal, podía mejorar el rendimiento de los idiomas con pocos recursos debido a la diversificación de los datos sintéticos generados. En ese sentido, y para entrenar el modelo NLLB-200, que dispone de 54.000 millones de parámetros, Meta empleó su nuevo Research SuperCluster (RSC), uno de los superordenadores de IA más rápidos del mundo.



