
Fotomontaje inspirado en Gemini 2.5 Pro
Google deja a ChatGPT en ridículo al presentar su nueva IA, 2.5 Flash-Lite, y anuncia la versión final de Gemini 2.5 Pro
Gemini 2.5 Flash y Pro ya están disponibles en su versión final y se introduce 2.5 Flash-Lite, el modelo de mejor coste-eficiencia y "2.5" más rápido.
Más información: Google anuncia la edición I/O de Gemini 2.5 Pro, la IA que ha dejado en ridículo a ChatGPT en escritura y programación
Hace menos de dos semanas Google actualizó 2.5 Pro de nuevo y avisó que en menos de dos semanas llegaría la versión final de la IA que ha puesto contra las cuerdas a ChatGPT. Ahora lo anuncia y también introduce 2.5 Flash-Lite.
Gemini 2.5 es una familia de modelos de razonamiento híbridos que en los dos últimos meses ha dejado claro su potencial y su gran rendimiento. Incluso frente a la renovación de DeepSeek R1.
Hoy es el día en el que finalmente llega la versión final de las pruebas que ha estado llevando a cabo Google con Gemini 2.5 Pro y los modelos flash. Y ya está disponible un previo de 2.5 Flash-Lite.
Este modelo es el de mayor eficiencia por coste y el "2.5" más rápido lanzado hasta la fecha por el gigante de las búsquedas online.
A Gemini 2.5 Pro ya lo conocemos bien después de estos dos meses en que ha dejado bien claro su capacidad para la codificación y la escritura creativa, así que es el momento de Gemini 2.5 Flash-Lite.
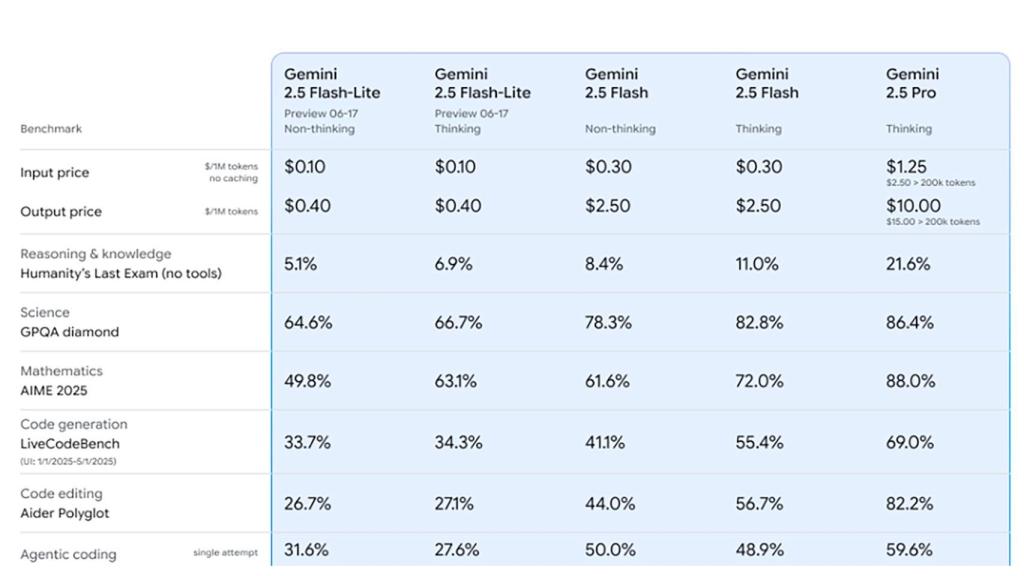
El coste de la familia Gemini 2.5
El previo ya está disponible según Google en su blog, y 2.5 Flash Lite mejora en todos los aspectos a lo que ha sido 2.0 Flash en codificación, matemáticas, ciencia, razonamiento y multimodal.
Donde destaca enormemente es en tareas de gran volumen y sensibles a la latencia como traducción y clasificación, y con menor latencia que 2.0 Flash-Lite y 2.0 Flash en una amplia gama de ejemplos de prompts.

Llega con multitud de herramientas y capacidades disponibles en Gemini 2.5 como activar el razonamiento profundo en distintos presupuestos, la conexión con Google Search y la ejecución de código, entrada multimodal y ofrece una longitud de contexto de un millón de tokens.
De hecho, en algunas gráficas compartidas por Google desde el documento técnico, deja bien claro que en tokens de salida por segundo sobrepasa al resto de la competencia por mucho (la cantidad de tokens que genera cada segundo al producir una respuesta).
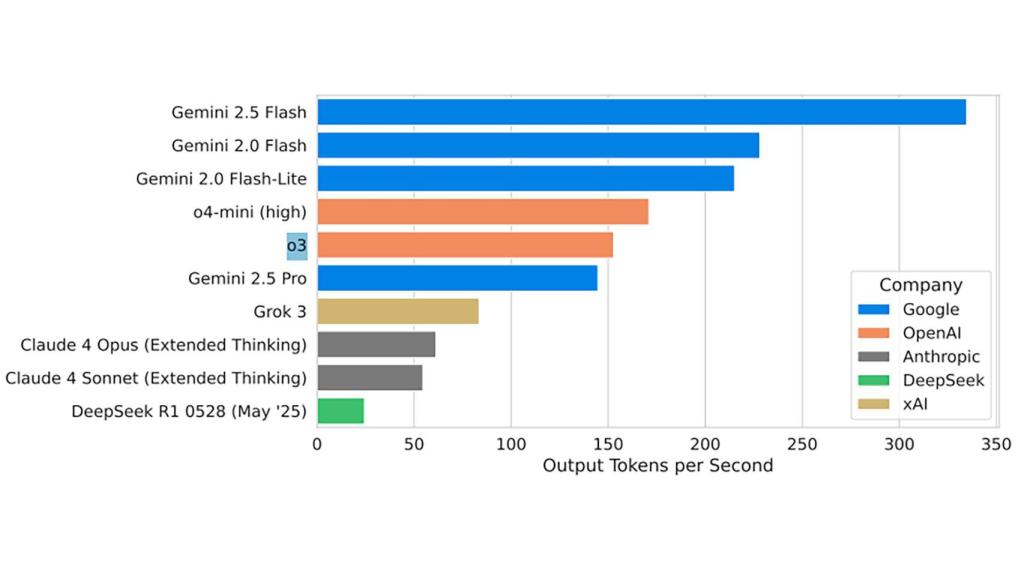
La comparativa de tokens de salida por modelo de IA
En eficiencia coste es uno de los modelos más interesantes para desarrolladores de terceros y el único que compite en este sentido es DeepSeek R1.
Para entenderlo mejor, si Gemini 2.5 Pro exige 1,25 dólares por 1 millón de tokens, Gemini 2.5 Flash-Lite se queda en los 0,10 dólares. Una diferencia importante cuando hay que prever costes en los servicios de terceros.
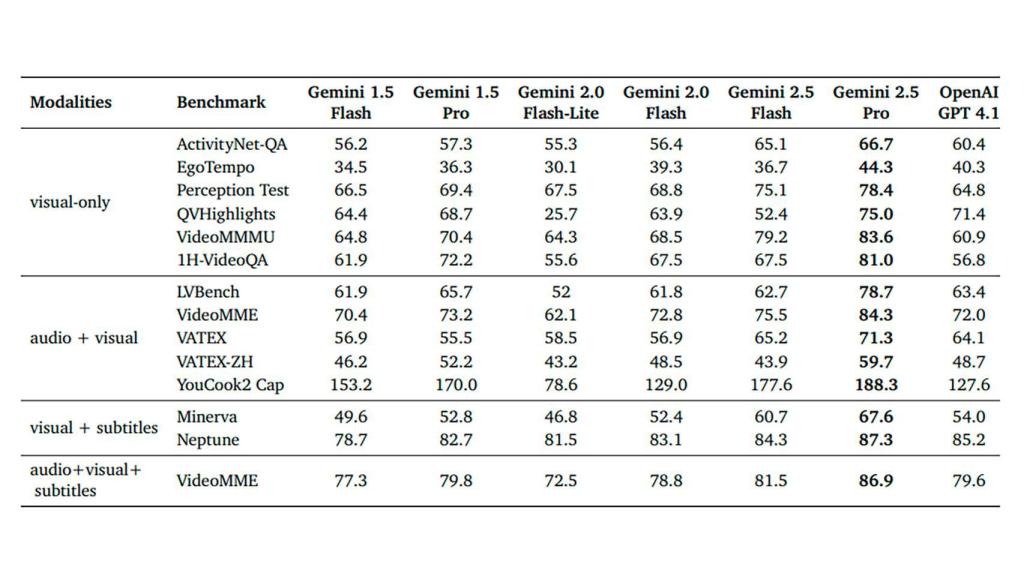
Comparativa en visual y audio frente a GPT 4-1.
Google sí que no ha dado ninguna tabla de referencia general para compararlo con otros modelos de IA como los de Anthropic, OpenAI o el mismo DeepSeek R1. Se ha basado en mostrar las capacidades de 2.5 Pro y Flash frente a GPT 4.1 en compresión de vídeo.
El previo de Gemini 2.5 Flash-Lite está ya disponible en Google AI Studio y Vertex AI, al igual que las versiones estables de 2.5 Flash y 2.5 Pro. Estos dos últimos ya están disponibles también desde la app Gemini.
Y un último detalle, las versiones custom de 2.5 Flash Lite y Flash llegan también a la búsqueda, ya sea a través de las respuestas de IA generativa o a través del polémico AI Mode.



