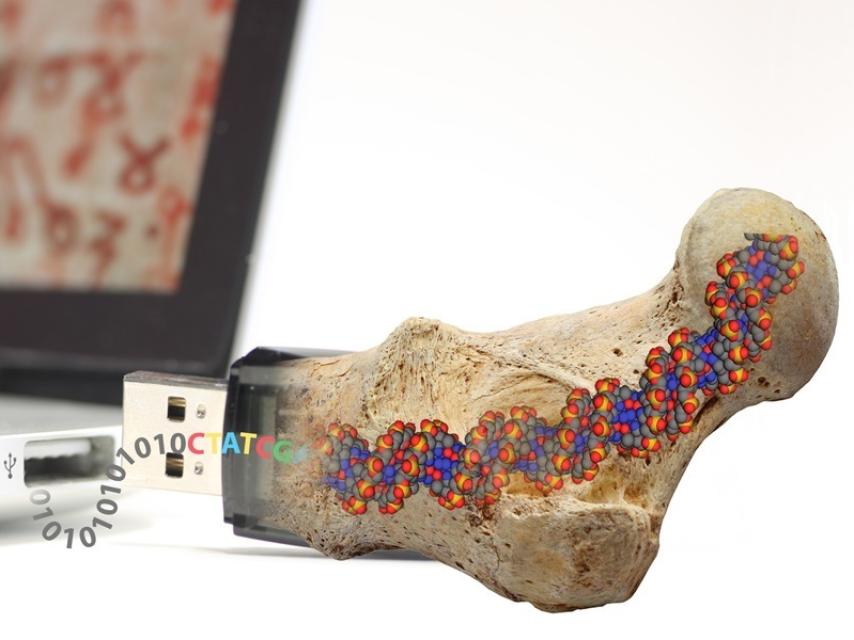
Los investigadores se inspiran en los fósiles a la hora de almacenar datos.
Adiós a la nube: el archivo digital del futuro es el ADN
Los investigadores exploran el almacenamiento de información en secuencias genéticas como alternativa a los soportes magnéticos y ópticos empleados hoy en los centros de datos.
Noticias relacionadas
Era una gran idea: aprovechar el 900 aniversario del Domesday Book, un registro general de Inglaterra completado en 1086 bajo el reinado de Guillermo I el Conquistador, para construir una gran biblioteca digital mutimedia sobre la vida cotidiana en Gran Bretaña. El ambicioso BBC Domesday Project, con un coste de 2,5 millones de libras, culminó en 1986 con la publicación de dos volúmenes con una capacidad total de 1.600 megabytes (MB), una barbaridad para su época, equivalente a más de 1.000 disquetes de entonces.
El error fue el soporte elegido: LaserDisc. En aquel momento era un formato novísimo, futurista y muy prometedor. Diez años después, prácticamente había desaparecido del mapa. En 2002 el diario The Guardian titulaba: "El Domesday Book digital dura 15 años, no 1.000". Ya no quedaba un sólo reproductor capaz de leer los discos del proyecto, que requerían además el uso de una computadora especial. Comenzó entonces el penoso trabajo de recuperar los datos para adaptarlos a otros soportes. En 2011, por fin Domesday Reloaded estuvo, esta vez sí, disponible en internet para todo el público, un cuarto de siglo después de su publicación original.
Soportes obsoletos y frágiles
El LaserDisc siguió el mismo camino hacia el cementerio digital que han emprendido antes o después los floppies de 5¼, los de 3½, el Zip o el Jaz, por no hablar de la infinidad de formatos de cartuchos ROM de mil y una consolas hoy desaparecidas, o de los soportes específicos para audio o vídeo como el MiniDisc o el MiniDV. Hoy incluso el CD, el DVD y el Blu-ray son ya reliquias del pasado para los más jóvenes. Todo lo cual plantea un problema: ¿dónde almacenar hoy los datos digitales para que duren los 1.000 años del Domesday original?
A la obsolescencia tecnológica se une el propio deterioro de los soportes físicos. Todos tenemos la experiencia de que los CD y los DVD no son para toda la vida, como creímos que nos habían prometido. Los discos duros duran lo que dura el ordenador, y las memorias flash son cómodas y portátiles, tanto que solemos perderlas. Hoy se nos aconseja el almacenamiento en la nube, pero este término etéreo es engañoso: al otro extremo del cable siempre debe existir un soporte físico. Para el almacenamiento a largo plazo, los grandes centros de datos emplean cartuchos de cinta magnética que ya alcanzan capacidades de hasta 185 terabytes (1 TB es igual a 1.000 GB) y ofrecen la mayor densidad de almacenamiento disponible hoy en el mercado. Pero su vida media alcanza sólo unos ridículos 30 años.
Otra amenaza para el almacenamiento de datos es que el volumen de información digital a conservar se está disparando exponencialmente. Según las compañías EMC Corporation e International Data Corporation, en 2013 el universo digital ocupaba 4,4 zettabytes (1 ZB es igual a un billón de GB); para 2020 esta cifra se habrá multiplicado por 10 hasta 44 ZB; casi tantos bits digitales como estrellas hay en el universo, y que llenarían la memoria de más de seis pilas de tablets desde la Tierra a la Luna. El problema, advierten estos expertos, es que la capacidad instalada de memoria no está creciendo al mismo ritmo.
Un sistema que nunca caducará
Por todo ello, algunos investigadores están volviendo sus ojos hacia un soporte de almacenamiento de datos que lleva existiendo miles de millones de años, que alcanza una densidad de información 100 millones de veces mayor que las cintas magnéticas (1.000 millones de GB por milímetro cúbico frente a 10 en las cintas), que puede durar siglos o incluso milenios y, más importante, que jamás se quedará obsoleto: al menos mientras los humanos sigamos aquí, siempre necesitaremos sistemas de síntesis y lectura de ADN.
El ADN es un soporte inventado por la naturaleza para almacenar datos. Consiste en una cadena de eslabones idénticos entre sí excepto por una etiqueta que llevan adosada y que se diferencia en cuatro tipos, a los que llamamos adenina (A), timina (T), citosina (C) y guanina (G). La secuencia particular de cada cadena de ADN en un gen forma un código que se traduce en una proteína. Pero basta aplicar métodos de encriptación para que una secuencia de ADN creada a voluntad pueda almacenar otro tipo de datos no genéticos; por ejemplo, digitales en código binario.
La idea de hackear el ADN para codificar datos es casi tan vieja como el descubrimiento de la propia molécula: fue propuesta por primera vez por el físico ruso Mikhail Samoilovich Neiman en 1964, pero no comenzaría a llevarse a la práctica hasta finales del siglo XX. En 1996, el artista e investigador del Instituto Tecnológico de Massachusetts Joe Davis ideó un método para traducir a ADN un gráfico formado por ceros y unos que representaba una runa germánica, o también un dibujo simplificado de los genitales femeninos; una Microvenus, como la denominó su creador.
Hackear la naturaleza
En 2008, el magnate de la biotecnología J. Craig Venter creó un genoma sintético de una bacteria en el que incluyó una especie de marcas de agua, secuencias que codificaban los nombres de los investigadores y varias citas de personajes célebres. Un equipo de la Universidad de Hong Kong presentó dos años después un sistema para introducir textos en bacterias, convirtiéndolos en caracteres ASCII en código binario y después encriptándolos en forma de secuencias de ADN. Los autores calculaban que un gramo de bacterias podía almacenar la información contenida en 450 discos duros de 2 TB.

En el material rosado de la derecha pueden almacenarse 10.000 gigabytes.
En la presente década otros investigadores han avanzado aún más, convirtiendo en ADN sonetos de Shakespeare, clips de audio de Martin Luther King, fotografías o fragmentos de la Wikipedia. En febrero de 2015, un equipo del Instituto Federal Suizo de Tecnología en Zúrich tradujo a ADN el Pacto Federal Suizo de 1291 y una obra de Arquímedes. En lugar de bacterias como los investigadores chinos, emplearon ADN desnudo, pero encapsulado en vidrio de sílice para crear fósiles artificiales capaces de conservar los datos durante al menos 2.000 años, que podrían aumentar a dos millones de años si se guardaran a temperaturas de -18 oC.
La última aportación acaba de ser presentada en la 21ª Conferencia Internacional de Soporte Arquitectónico para Lenguajes de Programación y Sistemas Operativos (ASPLOS), celebrada a comienzos de abril en Atlanta (EEUU). Los investigadores, de la Universidad de Washington y la división de investigación de Microsoft, han grabado cuatro imágenes en secuencias de ADN. Una vez convertido el código binario a genético, se rompen estas secuencias en cadenas cortas que pueden crearse con un sintetizador de ADN. A estos fragmentos se les añaden pequeñas secuencias que sirven como etiquetas de dirección o "códigos postales" para poder localizarlas a voluntad, como hace la memoria RAM (Memoria de Acceso Aleatorio) de los dispositivos eletrónicos.
Una vez almacenado el ADN, para deshacer el proceso y recuperar la información se utilizan pequeñas moléculas que pescan las direcciones deseadas, y los fragmentos de interés se leen con un secuenciador de ADN para después convertirlos de nuevo a código binario. Según la Universidad de Washington, la información digital que en los soportes actuales llenaría el espacio de un hipermercado ocuparía lo que un terrón de azúcar en forma de ADN.
El ADN reemplazará a las cintas
Los investigadores aún exploran tierra incógnita, en la que quedan infinidad de obstáculos por resolver y estándares que adoptar. Entre estos están las opciones de emplear ADN desnudo o de introducirlo en bacterias. "Las bacterias se replican, así que es fácil mantener el sistema, pero tienen una capacidad limitada e incorporan mutaciones", señala a EL ESPAÑOL el profesor de la Universidad de Edimburgo (Reino Unido) Sotirios A. Tsaftaris, que no ha participado en el nuevo estudio. Por su parte, el coautor del trabajo Georg Seelig, de la Universidad de Washington, subraya que con el ADN desnudo "la densidad de la información es mayor, y tanto el almacenamiento como el acceso a la información son más fáciles".
Para Seelig, el principal reto tecnológico está en la síntesis del ADN, un proceso que aún resulta demasiado largo y costoso. En cuanto a la lectura o secuenciación del ADN, ha avanzado enormemente desde el Proyecto Genoma Humano a comienzos de este siglo, pero Seelig cree que en el futuro "será interesante construir un sistema integrado que pueda explotar la alta densidad de almacenamiento, pero también permitir un fácil acceso y reposición de los datos"; es decir, algo parecido a los sistemas de los centros de datos automatizados, donde los robots buscan y recuperan las cintas para introducirlas en los lectores. Tsaftaris apunta que el gran avance llegará cuando el mundo del ADN y el de la electrónica puedan "enlazarse sin discontinuidades, sin tantos pasos químicos entre ambos".
En cualquier caso, el uso de un soporte químico siempre impone un proceso más largo que la electrónica pura. "Leer y escribir ADN lleva mucho tiempo, actualmente unas diez horas, así que no es apropiado para aplicaciones que requieran un acceso rápido y regular a los datos", aclara Seelig. "Sin embargo, es una tecnología realmente prometedora para el almacenamiento de archivos a largo plazo", añade; "confiamos en que el ADN podría reemplazar a las cintas". En su estudio, los investigadores vaticinan un futuro de sistemas híbridos que aunarán la tecnología del silicio y la bioquímica. "Ha llegado el momento de que la computación incorpore biomoléculas como parte integral del diseño de los ordenadores", concluyen.