
Ilustración con los logos de DeepSeek y ChatGPT en un teléfono móvil. Reuters
Apple encuentra fallos a ChatGPT y DeepSeek: los modelos que razonan colapsan ante problemas complejos
Un estudio de investigación de Apple detalla las limitaciones de los grandes modelos de IA actuales: "razonan de manera inconsistente" entre acertijos.
Más información: ChatGPT se actualiza a lo grande con una nueva IA que 'razona': así son o1-preview y mini, disponibles ya en España

En el último año, los modelos de lenguaje de razonamiento (LRM) se han presentado como la nueva frontera para superar algunas de las limitaciones de los grandes modelos de lenguaje (LLM) que impulsaron el uso de los chatbots en todo el mundo. La carrera es frenética, entre OpenAI, DeepSeek, Claude, Gemini y otros, pero esta tecnología también presenta dificultades.
Los LRM se han presentado como la IA capaz de realizar cadenas de razonamiento similares a las de los humanos, una técnica con la que evitar ciertos errores o alucinaciones. Un nuevo estudio realizado por investigadores de Apple refleja que estos modelos tienen una capacidad más limitada de la que se pensaba.
Apple ha puesto a prueba los principales modelos de IA con razonamiento como Claude 3.7, DeepSeek R1 y o3-mini. Los ha comparado también con los grandes modelos de lenguaje sin razonamiento de estas empresas. Este estudio se trata de la continuación del primer trabajo realizado el año pasado por los mismos investigadores.

El estudio concluye que ambos tipos colapsan cuando se aumenta la complejidad de la tarea, mientras que en tareas de baja complejidad los modelos estándar (LLM) sorprendentemente superan a los LRM. Solo en ciertas tareas de complejidad media, el pensamiento adicional en los LRM demuestra ventaja frente a los LLM.
El equipo de Apple ha descubierto que los modelos no consiguen escalar sus capacidades de razonamiento como los humanos, sino que tienen un límite. Incluso cuando todavía cuentan con tiempo de computación disponible, estos modelos se dan por vencidos llegado ese punto crítico.
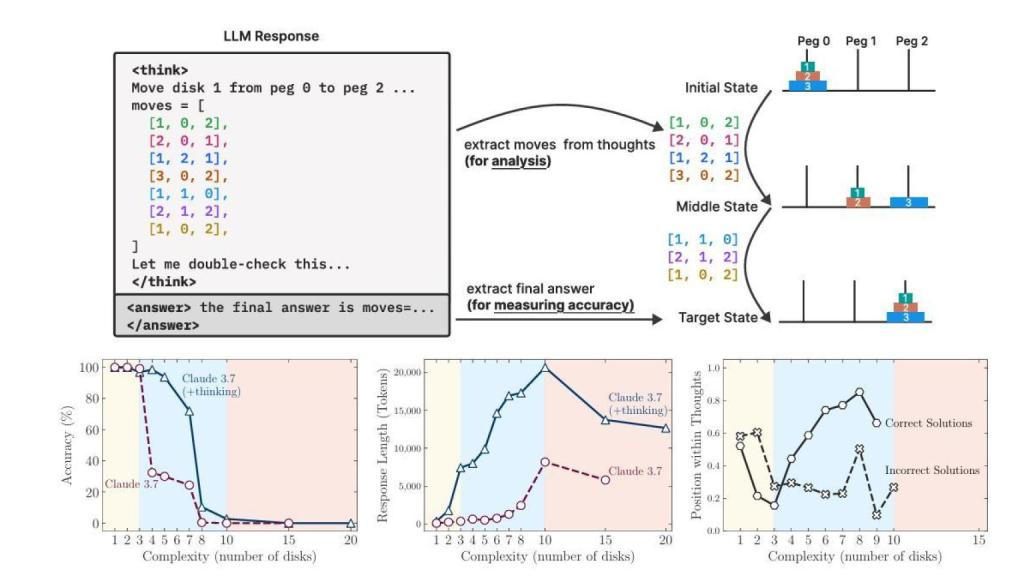
Rendimiento de Claude 3.7 ante la Torre de Hanoi Omicrono
Una de las pruebas a las que ha sometido Apple a estas inteligencias artificiales es el rompecabezas de la Torre de Hanói. Inventado por el matemático francés Édouard Lucas en 1883. Y la IA clásica lo resolvió en 1957. Se trata de un juego clásico con tres clavijas y varios discos en el que debes mover todos los discos de la clavija izquierda a la clavija derecha, nunca apilando un disco más grande encima de uno más pequeño.
Un niño pequeño puede conseguirlo con un poco de paciencia, pero Claude, por ejemplo, no llega a trabajar con 7 discos, consiguiendo menos del 80% de precisión. Tampoco o3-mini conseguía resultados mucho mejores ante este problema.
5/ models "overthink" EASY problems—exploring WRONG answers after finding the RIGHT one.
— Josh Wolfe (@wolfejosh) June 7, 2025
And when problems get HARDER… they think LESS.
Wasted compute at one end––defeatism at the other
El experto en inteligencia artificial, Gary Marcus, explica en una entrada de su blog que el artículo científico de Apple, demuestra que los algoritmos LLM no sustituyen a los buenos algoritmos convencionales bien especificados. Esta tecnología sigue siendo útil para tareas como generar código, lluvia de ideas y escritura, todo contenidos que deben ser luego revisados. Para tareas más complejas aún están en duda.
Diferentes voces de la industria están opinando sobre este nuevo estudio, muchos reconocen la importancia de lo desvelado por Apple, pero se han creado dos vertientes: los que consideran que esto demuestra un estancamiento de las capacidades de los LLM, mientras los que confían que su desarrollo futuro solvente estas deficiencias.



