
La mayor parte de actuales usuarios, sobre todo las generaciones más jóvenes, que se conectan a la red no tiene ni idea de su verdadero origen. Y es bueno refrescar ahora, casi 50 años después, sus inicios.
En realidad a lo que llamamos Internet se originó en dos planos, por una parte la infraestructura de red que sirve o da soporte a su funcionamiento, y sobre esa infraestructura lo que llamamos Internet en realidad, se podría definir como un conjunto descentralizado de redes interconectadas que une la familia de protocolos de red TCP/IP que fue demostrada por primera vez en 1972 por el Departamento de Defensa de EE.UU.
En 1972, Robert E. Kahn fue contratado por la 'Oficina de Técnicas de Procesamiento de Información' de la agencia gubernamental DARPA (Agencia de Proyectos de Investigación Avanzados de Defensa) responsable de desarrollo de nuevas tecnologías para uso militar, que a su vez fue creada como consecuencia tecnológica de la llamada Guerra Fría, y de la que surgieron los fundamentosde ARPANET, la red de ordenadores conectada entre sí desarrollada por el Departamento de Defensa de EE.UU. que dio origen al actual Internet.
Su primer nodo fue creado en la Universidad de California en su campus de Los Ángeles (UCLA) y fue la espina dorsal de Internet hasta 1990.
En la primavera del año 1973, Vinton Cerf desarrollador del protocolo de red de ARPANET se unió a Kahn y juntos desarrollaron la citada familia TCP/IP que provee de conectividad a cualquier conexión en la red Internet de extremo a extremo, determinando cómo los datos deben ser formateados, direccionados, transmitidos, enrutados y recibidos por el usuario de cualquier conexión en la red de redes.
Y eso sigue funcionando hasta hoy, mantenido por la Internet Enginnering Task Force (IETF), creado en EE.UU. en 1986, que es una institución sin ánimo de lucro, abierta a la participación de cualquier persona y cuyo propósito es regular los estándares de Internet (RFC) y velar por que la arquitectura de red y los protocolos que la conforman funcionen correctamente.
Este proceso que describo fue el que hizo que Internet pasara de su origen militar a un uso civil, universal y abierto a todo el mundo.
Las universidades de EE.UU. que se conectaron entre sí mediante TCP/IP formando el primer grupo de nodos fueron con su uso de crecimiento exponencial las que confirmaron un uso de Internet como uno de los instrumentos más universales de comunicación a distancia entre humanos, no importa en qué lugar del planeta se encuentren.
En abril de 2021, exactamente 49 años después de la primera demostración del TCP/IP Internet, 4.330 millones de habitantes, de los 7.000 millones ya estaban conectados y usando Internet. Nunca antes la humanidad tuvo un instrumento así.
La Web humana
Se suele llamar coloquialmente a Vint Cerf y a Bob Khan los 'abuelos de Internet', para coloquialmente, luego, poder llamar algo así como 'padre de Internet' al inventor de la Web, Tim Berne’s-Lee que desarrolló, aprovechando la 'cibernética de red' generada por el trabajo de estos dos abuelos de la red, entre marzo y diciembre de 1989, -17 años y medio después de la 'demo' de la pila de protocolos TCP/IP–, la World Wide Web.
En resumen, la web, que es un sistema que funciona a través del Internet originario citado al que sumó un nuevo y decisivo protocolo, denominado 'Protocolo de Transferencia de Hipertextos o HTTP (Hipertext Markup Language)', pero que no solo es un protocolo de comunicaciones sino todo un lenguaje de marcas que permite cerrar documentos para compartir a través de Internet, empleando un sistema que Berners-Lee denominó de Localización Uniforme de Recursos (URL), que es la dirección concreta que determina cada uno de los recursos que puedes encontrar en la red, es decir, un identificador propio para cada página, documento o archivo, publicada en el Internet en base a esta sistema.
Hoy resulta casi increíble que en su Oficina del CERN, el investigador de informática británico Tim Bernard-Lee, con la ayuda de su colega belga Robert Cailleau, desarrollaran en solo 9 meses de 1989 la Web, que fue publicada oficialmente en 1991, una herramienta de comunicación en red tan poderosa que hoy, treinta años después, en el momento de escribir este artículo, en número de páginas web al que se opuse acceder es, exactamente, 1.893.218.550 paginas Web distintas, cada una de ellas con su dirección o URL específica.
Estas webs, además, ya no son alfanuméricas como en sus principios sino completamente audiovisuales. Por tanto, esa internet que sigue funcionando e interconectando a dos tercios de la humanidad se ha convertido en una Web humana y universal, más allá de idiomas, culturas y geografías.
Pero hay que olvidar que el lugar donde Bernard-Lee inventó la Web fue el CERN: el lugar de Europa donde se ha construido desde la óptica civil, al contrario que ARPANET.
Además de eso, al CERN le caracteriza otra cosa muy importante: todos su hallazgos se declaran oficialmente patrimonio de toda la humanidad, así que la Web inventada allí, es de libre uso para todo el género humano.
En paralelo a lo descrito, se inventaron los buscadores, y 15 años después de inventada la Web en el año 2004, Tim O’Reilly formuló a Web 2.0, o lo que hoy llamamos el internet social que ha dado forma al 'Internet de las redes sociales' tal como lo conocemos ahora. Incluidos los buscadores cuyo principal paradigma fue el de Google.
Y también ha habido desarrollos de empresas y plataformas de red basadas en la web que se desarrollaron y se usan por miles de millones ya no solo desde ordenador sino desde los teléfonos inteligentes o desde cualquier máquina digital en base a la tecnología web -combinando otras- cualquier humano desde cualquier país del planeta puede comunicarse, compartir contenido, jugar online, relacionarse de mi maneras, todo virtualmente.
Pero la tecnología básica universal que da soporte a todo ello es la basada en la web. Una web con curva de aprendizaje es casi cero, que comunica y permite interactuar a las personas entre sí a distancia a través de sus dispositivos conectados a internet.
Puede usarse para lo mejor, pero también puede que para lo peor (Deep Web). Pero ante todo es una Web para humanos; Una Web humana.
Del Internet de las Cosas al Internet de Todo
Hasta hace muy poco siempre se había pensado en Internet como un medio de interacción entre humanos. Para eso se pensó y desarrolló. Pero en paralelo a esta Web Humana han ido surgiendo paralelamente otras formas de Internet que no son exclusivas del uso de humanos o entre humanos.
Desde ese paradigma estamos gracias a nuevos desarrollos tecnológicos que afectan a internet, que combinan crecientemente su uso por humanos con el Internet usado solo por máquinas; primero genéricamente con los artefactos que también pueden ser y permanecer conectados.
Y no solo ordenadores o teléfonos que manejan los humanos en su conexión a la red sino todo tipo de 'cosas' conectadas a Internet y accesibles a través de él.
Es decir, 'Objetos electrónicos' que son susceptibles de ser identificados, accedidos y gestionados por otros equipos, dispositivos o software como si lo fueran por humanos, aunque también.
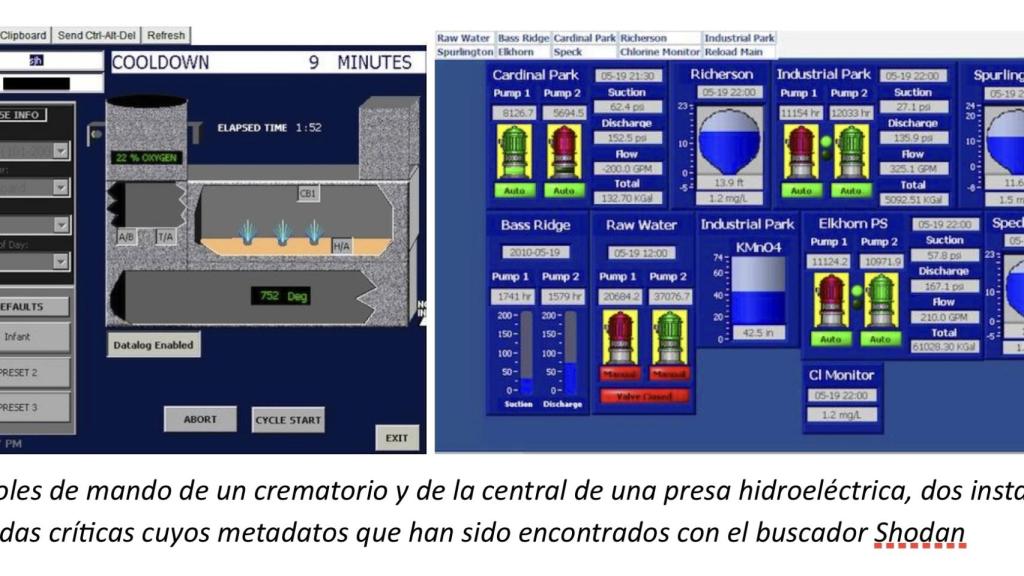
Los controles de mando de un crematorio y de la central de una presa hidroeléctrica.
En realidad esto forma un 'corpus de internet' completamente cibernético, un auténtico Internet de las máquinas, que puede estar bien al margen, o interrelacionándose también con el internet citado de la Web humana.
Esto no es nuevo y y la convivencia entre humanos y máquinas en su presencia virtual en la red se está decantando del lado de estas a lo largo de esta última década.
Ya en 2012 un estudio de Incapsula mostró que ya entonces el 51% del tráfico de Internet no era ya de origen humano. Hoy ese porcentaje ha aumentado hasta los dos tercios del total. Nicholas Negroponte ya lo auguró con una bonita frase de doble sentido que se hizo famosa.
Dijo: "En unos años habrá más Barbies conectadas a internet que personas". Fue un augurio que resumía una promesa anterior en Kevin Ashton que en 1999 ya le puso nombre: Internet of Things (IoT), que en español, genéricamente, es Internet de las Cosas.
Si sumamos la ideas de conexiones de objetos (o sea, no de-personas) de este IoT, y lo del tráfico no humano que coloniza Internet podemos afirmar, sobre todo por el uso de la inteligencia artificial y de todo tipo de entidades digitales, agentes y robots de software, que Internet ya no es mayoritariamente humano, la actividad no humana que puebla internet ya es mayor que la actividad de los humanos en la red.
Y ¿cuál es el siguiente paso en esa dirección? Pues, igual que está creciendo el Internet de las cosas conectado a la red, van emergiendo herramientas que no solo se ocupan de la parte humana sino de la parte de las cosas. Que hay en Internet y conectada a internet.
Y como sucede en la parte de al Web humana donde hay usos fantásticos que las personas hacen de la web también los hay inquietantes (lease malos usos de las redes sociales, o usos perversos y oscuros de la Web profunda, o Deep Web, también ocurre lo mismo con el Internet de las Cosas que si bien puede proporcionar todo tipo de cosas positivos, también está emergiendo un 'lado oscuro de este Internet de las cosas'.
Y tiene que ver con una evolución de ese concepto que combina la parte física que servía ese internet de 'cosas' conectadas con los datos que generan el tráfico no humano de la red a la que me refería antes.
A ese marco más holístico que combina lo físico (las cosas) con lo inmaterial -el software, los datos- que se manejan a gran escala, por ejemplo con el Cloud global, y con algo muy importante, los 'metadatos' (banners), es decir, "los datos sobre los datos" que sobre todo manejan las máquinas o el software.
A este conjunto se le ha empezado a llamar el Internet of Everytings. IoE ('Internet de todo'). Es algo que también lleva conviviendo con el uso humano de la Web e Internet y se puede originar, gestionar o actuar directamente en el lenguaje de las máquinas.
Formas de internet inquietantes
Una polémica reciente nos puede dar pistas sobre lo inquietante que puede ocurrir si se combinan para el bien o para el mal. La polémica es sobre el motor de búsqueda Shodan, que no es nuevo pero sus mejoras recientes le hacen capaz de rastrear no solo datos sino metadatos de los objetos del internet de las cosas y combinarlo con la parte de usuarios humanos de Internet.
Shodan, según su página web, obtiene la mayor parte de los datos de los banners que son metadatos sobre el software que se ejecuta en un dispositivo conectado a la red.
Supuestamente, desde un punto de vista positivo, dicho buscador permite conocer a sus usuarios si existe una configuración de defensa de seguridad en los puertos que persisten el acceso desde el exterior o exponer datos, o sea si tiene alguna vulnerabilidad, desde el punto de vista de seguridad informática…
Pero también puede ser usado no solo para encontrar las vulnerabilidades de instalaciones o sistemas conectados a Internet, que es lo que promueve su creador John Martherly sino, según sus críticos, también para, una vez encontradas y localizadas en su ubicación física, tomar el control de ellas a distancia. Algo que puede ser muy peligroso si se trata de las llamadas ‘infraestructuras críticas’ de una región o país.



